

OpenCLIP 核心定义
OpenCLIP 是 OpenAI 经典跨模态模型 CLIP(Contrastive Language-Image Pre-training)的开源实现版本,由 UW、Google、Stanford 等机构的研究者主导开发,目标是复现并扩展 CLIP 的能力,同时开放预训练模型、训练代码和配套工具链,让开发者无需依赖 OpenAI 闭源接口即可使用跨模态(图像 – 文本)对齐能力。
核心特性
-
跨模态对齐核心能力
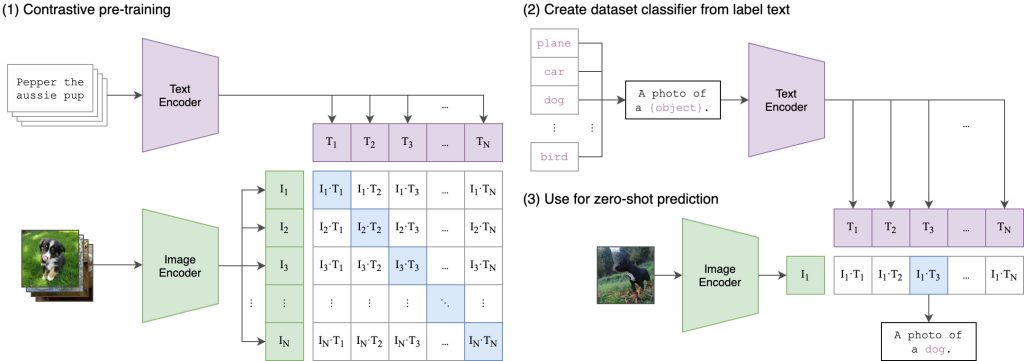
核心逻辑是通过对比学习训练模型,让「图像特征」和「文本特征」在同一向量空间中对齐:
- 输入图像 → 模型输出图像特征向量;
- 输入文本 → 模型输出文本特征向量;
- 计算两类向量的相似度,实现「文本检索图像」「图像检索文本」「零样本图像分类」等能力。
-
开源 & 可扩展
- 完全开源(MIT 许可证),支持商用和二次开发;
- 提供远超 OpenAI 原版 CLIP 的预训练模型库(如 ViT-B/32、ViT-L/14、MobileCLIP、CoCa 等),训练数据覆盖 LAION-400M/2B、DataComp-1B 等大规模数据集,部分模型 ImageNet 零样本分类精度达 85.4%(远超原版 CLIP 的 75.5%)。
-
多场景适配
- 支持轻量级模型(如 MobileCLIP-B),适配端侧 / 低算力场景;
- 内置 CoCa 模型分支,支持图像生成文本(图文描述);
- 兼容多语言文本、不同分辨率图像(224px/384px/448px 等)。
核心用途
| 典型场景 | 落地方式 |
|---|---|
| 零样本图像分类 | 无需标注数据集,直接用文本标签(如 “猫 / 狗 / 汽车”)匹配图像特征,实现分类; |
| 跨模态检索 | 文本关键词检索相似图像,或图像检索相似文本描述; |
| 图像文本生成(Caption) | 基于 CoCa 分支模型,输入图像生成自然语言描述; |
| 自定义跨模态训练 | 提供完整训练代码,支持基于自有图文数据集微调模型; |
技术架构(核心简化版)
OpenCLIP 的核心模型类
CLIP 由两大模块组成:- 视觉塔(Vision Tower):负责编码图像,输出图像特征(如基于 ViT/ConvNeXt/MobileCLIP 等骨干网络);
- 文本塔(Text Tower):负责编码文本,输出文本特征(基于 Transformer + 文本 token 嵌入);
- 额外通过
logit_scale等参数调节跨模态相似度计算,实现特征对齐。
github:
https://github.com/mlfoundations/open_clip
相关模型:
huggingface:
https://huggingface.co/laion/CLIP-ViT-L-14-laion2B-s32B-b82K
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END